在Pythonz中我们有可能需要去解析一个爬下来的HTML,我们在Python中应该如何去解析呢?
好在Python提供了HTMLParser来非常方便地解析HTML,只需简单几行代码:
# -*- coding: utf-8 -*-
from HTMLParser import HTMLParser
from htmlentitydefs import name2codepoint
class MyHTMLParser(HTMLParser):
def handle_starttag(self,tag,attrs):
print ('<%s>' % tag)
def handle_endtag(self,tag):
print ('</%s>' % tag)
def handle_startendtag(self, tag, attrs):
print('<%s/>' % tag)
def handle_data(self, data):
print('data')
def handle_comment(self, data):
print('<!-- -->')
def handle_entityref(self, name):
print('&%s;' % name)
def handle_charref(self, name):
print('&#%s;' % name)
parser = MyHTMLParser()
parser.feed('<html><head></head><body><p>Some <a href=\"#\">html</a> tutorial...<br>END</p></body></html>')
feed()方法可以多次调用,也就是不一定一次把整个HTML字符串都塞进去,可以一部分一部分塞进去。
特殊字符有两种,一种是英文表示的 ,一种是数字表示的Ӓ,这两种字符都可以通过Parser解析出来。
练习
找一个网页,例如https://www.python.org/events/python-events/,用浏览器查看源码并复制,然后尝试解析一下HTML,输出Python官网发布的会议时间、名称和地点。
这里我们要解析HTML之前,肯定要先获取该页面元素的代码.我们这里用到了urllib这个库,具体用法为:
# -*- coding: utf-8 -*-
import urllib
PythonPage = urllib.urlopen('https://www.python.org/events/python-events/')
pyhtml = PythonPage.read() #读取该页面代码.
print pyhtml

上面为结果,这里只是部分截图.
下面我们来继续研究上面的问题:
# -*- coding: utf-8 -*-
from HTMLParser import HTMLParser
from htmlentitydefs import name2codepoint
import urllib
class PyHTMLParser(HTMLParser):
def __init__(self):
HTMLParser.__init__(self)
self._count = 0
self._events = dict()
self._flag = None
def handle_starttag(self, tag, attrs):
if tag == 'h3' and attrs.__contains__(('class', 'event-title')):
self._count += 1
self._events[self._count] = dict()
self._flag = 'event-title'
if tag == 'time':
self._flag = 'time'
if tag == 'span' and attrs.__contains__(('class', 'event-location')):
self._flag = 'event-location'
def handle_data(self, data):
if self._flag == 'event-title':
self._events[self._count][self._flag] = data
if self._flag == 'time':
self._events[self._count][self._flag] = data
if self._flag == 'event-location':
self._events[self._count][self._flag] = data
self._flag = None #一定要设置为None,防止其它data误入
def event_list(self):
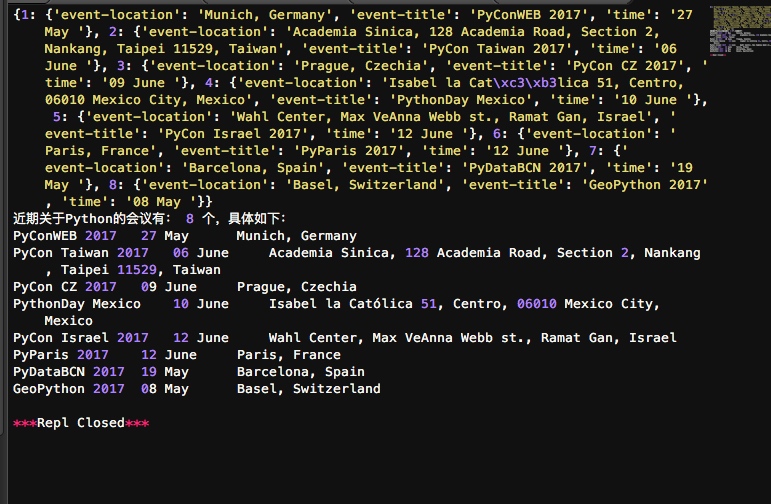
print self._events
print '近期关于Python的会议有:', self._count, '个,具体如下:'
for event in self._events.values():
print event['event-title'], '\t', event['time'], '\t', event['event-location']
PythonPage = urllib.urlopen('https://www.python.org/events/python-events/')
pyhtml = PythonPage.read()
parser = PyHTMLParser()
parser.feed(pyhtml)
parser.event_list()
这里我们将所遇到的属性,进行人为分类,将包含'event-title','time','event-location'关键字的属性聚类到一起,